Brief on why model checkpointing is even needed?
Training deep learning models is often backed with sufficiently large amount of data to learn patterns from, for example sensor data measurements collected through long hours of driving to enable autonomous cars. Artificial Intelligence (AI) which can generate algorithm has surpassed the performance of traditional approaches be it audio, vision, text, anomaly etc. Extreme rigor is required in deciding the model architecture and its evaluation as there exist numerous parameters to tune (considering MLP below):
- number of layers of a network
- number of neurons in each layer
- type of activation function
- optimization technique; associated parameters such as learning rate
- batch size
In general, the neural network models are trained to minimize the overall cost; comprising of miss-classification, regularization and other generalization constants. In each round of iteration the model parameters (i.e., weights representing neurons interconnection strengths) are updated using a mini-batch of samples. The training process is continued as long as the optimal parameters are not encountered. Figure below (taken from 1) spots an optimal point for which model should be saved and can be used for evaluating test error or its performance in real life settings.
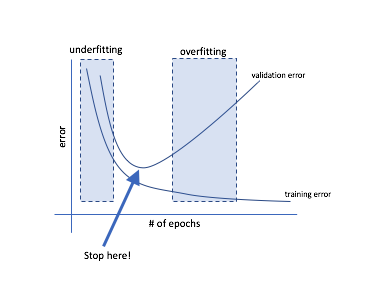
To look for the above Stop here point the model performance is evaluated after every nth iteration and if the validation loss improves the model parameters are saved. Alright, so how do we do this? This is where tensorflow comes handy
Checkpointing trained models
##=====================================##
## load relevant libraries ##
##=====================================##
import tensorflow as tf
prev_cost = 99999
saver = tf.train.Saver(max_to_keep=150) # initialize saver used for checkpointing trained model parameters
with tf.Session() as sess:
for epoch in range(no_of_epochs): # train model for n number of epochs
for iter in range(no_of_iters): # no of iterations depends on the mini batch and overall data size
batch_x, batch_y = iterator.next()
cost, _ = sess.run([mlp_cost, train_op], feed_dcit = {x: batch_x, y: batch_y})
if (iter+1)%10000==0: # Evaluate if model needs to be saved every 10000 iterations or so
val_cost = sess.run(mlp_cost, feed_dict = {x: val_x, y: val_y})
if (val_cost<prev_cost and val_cost>cost):
saver.save(sess,'/path/to/save/-mlp'+str(epoch) ,global_step = iter) # save model under defined condition
prev_cost = val_cost
The models can then be retrieved from the saved location and tested for accuracy over held-out dataset. For a given problem and a metric to be minimized or maximized the best performing model can be chosen for final production. Section next decribes steps to evaluate multiple saved models.
Evaluating saved checkpoints for performance
Checkpointing models at various iterations save three files with extension .meta, .index and .data alongwith file named checkpoint. Evaluating all the saved model performance involves following:
- Extract the model name from checkpoint file
- generate .pb file for each saved model
- Output predictions using .pb files and evaluate model performance
##===========little bit of regex to extract path and model identifier==============##
address = []
identifier = []
f = open('/path/to/save/checkpoint','rb')
for line in f:
path = line.split(":")[1]
address.append(re.findall(r'"(.*?)"',path)[0]
line = line.split('"')
identifier.append((line[0].split('-')[len(line[0].split('-'))-1])
##===========Generating .pb file using above identifier and path==================##
for path, id in zip(address, identifier):
id = int(id)
saver = tf.train.import_meta_graph(path+'.meta')
graph = tf.default_graph()
graph_def = graph.as_graph_def()
sess = tf.Session()
saver.restore(sess,path)
node_name = "..." # name of the node to be evaluated for a given input
graph_def = graph_util.convert_variables_to_constant(
sess, graph_def, node_name.split(","))
with tf.gfile.GFile(/path/to/save+str(id)+'.pb', "wb") as f:
f.write(graph_def.SerializeToString())
sess.close()
##===========using .pb file for predictions on test data==========================##
for model in (list_of_pb_files):
with gfile.FastGFile(model, 'rb') as f:
model_data = f.read()
with tf.Graph().as_default() as g:
graph_def = tf.GraphDef()
graph_def.ParseFromString(model_data)
tf.import_graph_def(graph_def, name='')
with tf.Session() as sess:
pred = sess.graph.get_tensor_by_name('node.name')
probs = sess.run(pred, feed_dict={'inp:0': x, ....) # feed_dict is given all the input needed to evaluate 'node.name'
Thus using probs from various saved models the performance metric is evaluated and the model with best metric on validation dataset is chosen.
Summary
In this post readers discovered a way to checkpoint best model parameters in training phase using tensorflow. Further how to convert all the saved models in .pb file in an automated fashion which could then be used to get model predictions and evaluate its performance on validation dataset. This is extremely important to spot the optimal trained model parameters in training phase and boost overall performance.