Brief to Generative and Discriminative models
Learning approaches can be broadly divided into two categories; generative and discriminative. Generative models learn the underlying distribution of data representing various categories for example, model may learn distribution of pixels in an image when a cat is present differently in comparison to presence of a dog. Thus, training generative model involves identifying following:
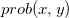
Ideally once the model learns the real underlying distribution it can be used to generate unseen samples which could further improve generalization capability of supervised techniques (discussed later). Discriminative models on the other hand models the conditional probability via relying heavily on the observed dataset for example, given the pixels arrangement in an image it learns to label an image as a cat or dog (considering two label calssification problems)
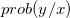
Generative models aids the unsupervised learning by improving the learned representations of observed samples corresponding to different classes.
Before we go on understanding how unsupervised learning can augment the supervised technique (or a classifier), I am tempted to quote following which fuels the need to reap the benefits unsupervised learning can deliver
“If intelligence was a cake, unsupervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake. We know how to make the icing and the cherry, but we don’t know how to make the cake”
Improving generalization using unsupervised technique
Unsupervised learning involves learning the representaions from observed samples with no information about their category or class. It tries to cluster the samples through its n-dimensional representations for example using auto-encoders, GANs. Assuming the task is to learn a classifier to distinguish between types of flowers, it proceeds in two steps:
- learn the n-dimensional representaion from given samples in an unsupervised manner
- Using learned representaions train a classifier to classify images of different types
To learn the representaions in an unsupervised fashion, GANs can first be trained to simulate images of flower by learning their underlying distribution (depcited below, taken from 1). Figure below is just for illustration, in reality each of the generator and discriminator components are many layer deep with other generalization layers such as batch normalization, dropouts.
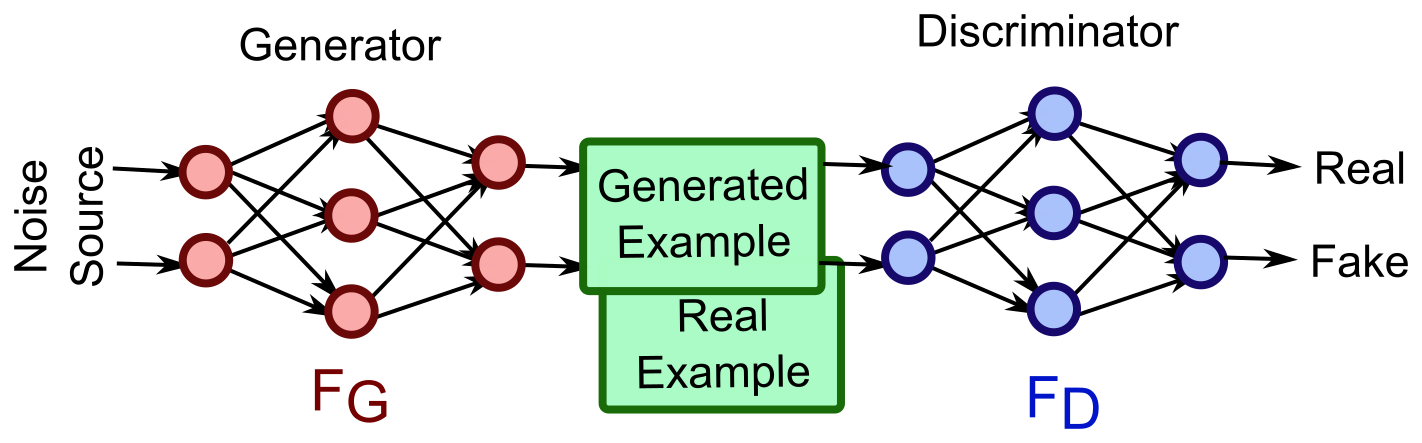
In figure above, real examples corresponds to observed flower images whereas generated is an output from trained generator. GANs are continuously trained as long as the generated samples gets closer to real. Once the training is over discriminator can then be used to feed all the observed samples to derive the n-dimensional learned representations (taken as second last layer output which contains n number of neurons). These representaions can then be fed to a classifier along with their desired labels for improved learning.
Supervised learning are thus benefitted with enhanced feature representations obtained using unsupervised method.
Semi-supervised method for training a classifier
Semi supervised technique has proven to be effective when enough labeled samples are not available. In the context of GANs this has been approached very well by changing the objective of discriminator. Assuming a MNIST classification problem, the final layer of discriminator outputs probability for each of the 10 labels. Thus when labeled samples are fed as an input to the discriminator, the discriminator cost is calculated using cross-entropy (indicated below using three layer architecture for discriminator). For the purpose of illustration one digit is indicated as an input, usually samples are fed in a mini-batch (typically of size 64, 128) and then cross entorpy loss is estimated to tune the discriminator weights.
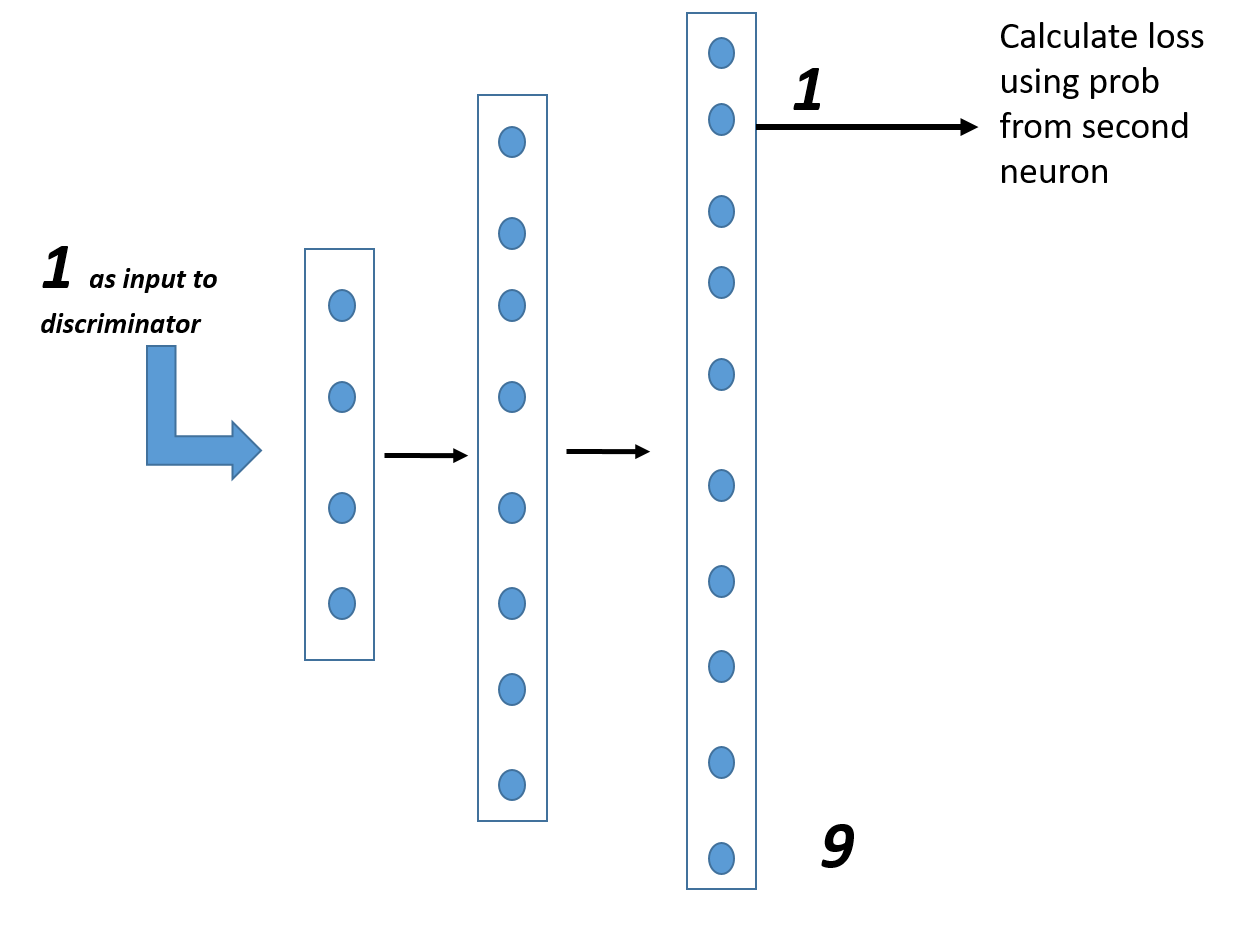
One might wonder by now, how is cost calculated for unlabeled samples?. Well my unlabeled samples could arise from real data or from generated samples, in such cases the discriminator is trained to minimize the summation of probs for all digits. This in turn allow discriminator to label them fake with high confidence. Contrary to this the job of the generator now becomes to generate samples so as to be able to increase the confidence of discriminator to label them as real (which is generally obtained by combining all the 10 output probs of a discriminator).
Summary
In summary the article discussed how Unsupervised and Semi-supervised learning can improve the Supervised learning. The article explained the relevant concepts as to how GANs are enabling these techniques to overcome the limitations faced by supervised approaches in following cases:
- Partially labeled samples are avaiable
- Generalizing well, when samples for a particular class is very limited thereby reducing its generalization